腾讯开源WeKnora,解锁复杂文档智能解析,知识管理进入AI新时代
腾讯近期正式开源了全新的文档理解与语义检索框架WeKnora(维娜拉)。这是一套专为结构复杂、内容异构的文档场景打造的智能问答解决方案,旨在为企业级文档问答提供高效、可控的端到端流程。
WeKnora采用现代化模块化设计,构建了一条完整的文档理解与检索流水线,涵盖文档处理、知识建模、检索引擎、推理生成以及交互展示等核心模块。
文档处理层负责多种格式文档的解析与预处理,将非结构化内容转换为结构化数据;知识建模层通过向量化、分块、知识图谱和索引等技术构建知识表示;检索引擎层集成多种检索策略,实现高效精准的内容召回;推理生成层利用大语言模型对检索结果进行理解和生成;交互展示层则提供直观的用户界面和标准API接口。
WeKnora的核心优势在于其多模态文档解析能力。该工具能够从PDF、Word、图片等多种格式文档中提取结构化内容,通过先进的语义处理技术将来自不同来源的信息整合成统一的语义视图。这一功能对处理包含文本、表格、图像等复杂结构的文档具有显著优势,能够大幅提升信息提取的效率和准确性。
相关链接
企业AI知识库搭建与运营培训课程
呼叫中心AI知识库培训课程
个人知识体系构建能力课程
知识库知识管理系统
企业AI知识管理知识库软件系统清单
个人知识管理软件AI知识库系统清单
核心模块包括:
- 文档解析引擎:支持多种格式的结构化提取
- 嵌入与向量索引:构建高精度语义空间
- 混合检索系统:融合关键词、向量与图谱策略
- 大模型推理层:结合上下文生成自然语言回答
- 评估与调试工具:端到端可视化测试与指标分析
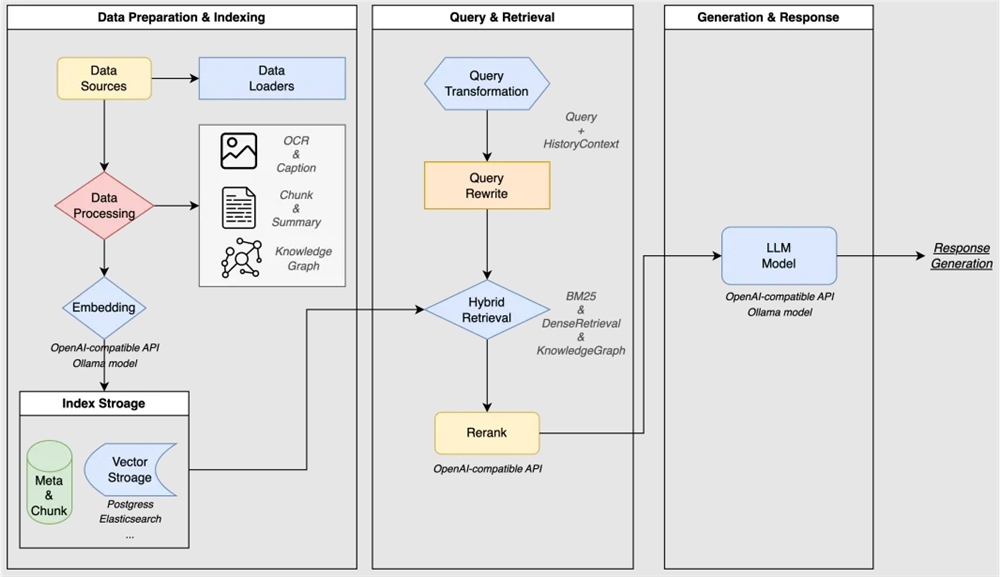
各组件之间高度解耦,支持按需替换和定制扩展,便于集成至不同技术栈或部署环境。
核心特性
| 特性 | 说明 |
|---|---|
| 🔍 精准理解 | 支持 PDF、Word、图片等复杂文档的内容提取,统一构建语义视图,保留表格、段落结构等关键信息 |
| 🧠 智能推理 | 借助大模型理解用户意图与上下文,支持多轮对话与复杂问题拆解 |
| ⚡ 高效检索 | 融合 BM25、稠密向量检索(Dense Retrieval)、GraphRAG 等多种策略,提升召回准确率 |
| 🔧 灵活扩展 | 从解析到生成全流程开放接口,支持自定义模型、数据库与服务集成 |
| 🎯 简单易用 | 提供直观 Web 界面与标准 RESTful API,零代码也可快速上手 |
| 🔒 安全可控 | 支持本地化部署、私有云运行,保障数据主权与合规要求 |
适用场景
WeKnora 尤其适用于文档类型多样、结构复杂、查询语义要求高的行业场景:
| 应用场景 | 典型应用 | 核心价值 |
|---|---|---|
| 企业知识管理 | 制度查询、操作手册检索、内部FAQ问答 | 提升员工效率,降低培训与沟通成本 |
| 科研文献分析 | 论文摘要提取、研究报告比对、学术资料检索 | 加速科研调研,辅助决策判断 |
| 产品技术支持 | 技术文档检索、故障排查指引、产品参数查询 | 缩短响应时间,减轻客服压力 |
| 法律合规审查 | 合同条款匹配、法规政策查询、案例参考 | 提高合规审查效率,降低法律风险 |
| 医疗知识辅助 | 医学指南查询、诊疗方案推荐、文献支持 | 辅助医生快速获取权威信息 |
功能模块能力一览
WeKnora 在关键环节均提供丰富支持,满足多样化部署需求:
| 功能模块 | 支持情况 | 说明 |
|---|---|---|
| 文档格式支持 | ✅ PDF / Word / Txt / Markdown / 图片(含 OCR & Caption) | 支持图文混排、扫描件文字识别与图像描述生成 |
| 嵌入模型支持 | ✅ 本地模型、BGE / GTE API 等 | 可切换不同 embedding 模型,兼容私有部署与云端调用 |
| 向量数据库接入 | ✅ PostgreSQL(pgvector)、Elasticsearch | 支持主流向量索引后端,便于性能调优与横向扩展 |
| 检索机制 | ✅ BM25 / Dense Retrieve / GraphRAG | 支持稀疏与稠密召回、知识图谱增强检索,支持组合策略 |
| 大模型集成 | ✅ Qwen、DeepSeek 等,支持思考/非思考模式 | 可接入本地模型(如 Ollama)或调用外部 API |
| 问答能力 | ✅ 上下文感知、多轮对话、提示词模板 | 支持指令控制、链式推理与上下文窗口管理 |
| 端到端测试支持 | ✅ 可视化链路追踪与指标评估 | 提供召回命中率、回答覆盖度、BLEU/ROUGE 等评估能力 |
| 部署模式 | ✅ 本地部署 / Docker 镜像 | 满足企业级私有化、离线部署需求 |
| 用户界面 | ✅ Web UI + RESTful API | 开发者与业务人员均可便捷使用 |
无论是企业内部的合同文档、科研领域的学术论文,还是医疗与法律行业的专业资料,WeKnora都能实现高效的内容解析与整合。这种跨模态的信息处理能力为传统文档管理带来了革命性的改进。
WeKnora基于大语言模型(LLM)构建,融合了多模态预处理、语义向量索引、智能召回与大模型生成推理等技术。其技术亮点包括强大的多模态认知引擎,能够精准解析PDF、Word、图片中的图文混排内容,提取文本、表格及图像语义信息,并融合OCR与跨模态建模技术构建统一的结构化知识中枢。
零代码接入微信生态
无需开发即可完成部署:
- 上传企业知识文档(PDF/Word等)
- 系统自动完成解析、索引与模型对接
- 在公众号、小程序中实现“即问即答”智能服务
高效问题管理
- 支持高频问题分类管理
- 提供回答质量监控与人工干预机制
- 内置数据看板,便于持续优化问答效果
全面覆盖微信场景
通过微信对话开放平台,WeKnora 的能力可无缝嵌入:
- 公众号自动回复
- 小程序客服机器人
- 企业微信知识助手
帮助企业快速构建可信、可控、可维护的 AI 问答服务。
模块化RAG流水线设计支持自由组合检索策略、大语言模型与向量数据库,能够无缝集成Ollama等平台,灵活切换Qwen、DeepSeek等主流模型,满足企业知识库的高效定制需求。精准推理与可信决策保障结合私有化部署、多轮上下文深度理解与全链路可视化评估,为高敏感场景提供可靠的知识支撑。此外,WeKnora还支持本地化部署和Docker镜像,兼容私有云及离线环境,内置监控日志体系,提供全链路可观测性,帮助运维人员高效管理。开箱即用的交互体验包括一键启动脚本和直观的Web UI界面,非技术用户也可以快速完成文档索引、智能问答等服务的部署与应用。
WeKnora广泛适用于多种企业级文档问答场景,包括企业知识管理、科研文献分析、产品技术支持、法律合规审查以及医疗知识辅助等。它提供了直观易用的Web界面,支持拖拽上传各类文档,自动识别文档结构并提取核心知识,建立索引。系统还支持知识图谱可视化,能够将文档转化为知识图谱,展示文档中不同段落之间的关联关系,提升检索结果的相关性和广度。
WeKnora的部署方式灵活多样。本地部署方面,它提供了完整的Docker化部署方案,用户只需通过简单的命令即可快速启动服务。此外,WeKnora作为微信对话开放平台的核心技术框架,还支持零代码部署,用户只需上传知识,即可在微信生态中快速部署智能问答服务,实现“即问即答”的体验。通过微信对话开放平台,WeKnora的智能问答能力可无缝集成到公众号、小程序等微信场景中,提升用户交互体验。
WeKnora采用MIT协议开源,欢迎社区用户参与贡献,无论是Bug修复、功能开发、文档改进还是用户体验优化,腾讯都期待大家的参与与反馈。
该项目地址为https://github.com/Tencent/WeKnora,感兴趣的开发者可以访问GitHub仓库,以便了解更多详情。
相关链接: