分类法(Taxonomies)与本体论(Ontologies)概念|关系|案例及其在LLM中的应用
编译/刘枫宁
分类法(Taxonomies):分类法是一种层次化的结构,用于组织和分类概念或实体,通常呈树状形式,从一般类别逐步细分到具体子类。
它强调“是一个”(is-a)的关系,例如一个概念是另一个概念的子集。
分类法的目的是简化信息检索、导航和组织,常用于内容管理系统中。
本体论(Ontologies):本体论是一种更全面的知识表示模型,不仅包括层次分类,还定义了概念之间的多种关系(如“部分-整体”关系、属性约束、规则和公理)。
它用于描述一个领域的知识结构,支持推理和语义分析,常基于形式化语言如OWL(Web Ontology Language)。
本体论的目标是实现机器可读的知识共享和自动化推理。
分类法和本体论的区别
- 结构复杂度:分类法通常是简单的单继承层次结构(树状),焦点在分类上;本体论支持多继承、复杂关系(如关联、因果)和属性定义,更像一个网络图。
- 功能深度:分类法主要用于组织和检索(如标签系统);本体论支持高级推理,例如自动推断新关系或检测不一致。
- 灵活性:分类法易于构建和维护,但扩展性有限;本体论更灵活,但开发更复杂,需要领域专家。
- 使用场景:分类法适合基本分类任务;本体论适用于需要语义理解的系统,如AI驱动的知识图谱。
总体而言,分类法可以视为本体论的简化子集,许多本体论从分类法扩展而来。
相关案例
- 分类法的案例:
- 生物分类系统(Linnaean Taxonomy):用于分类生物,从域(Domain)到种(Species),如将人类归类为动物界-脊索动物门-哺乳纲-灵长目-人科-人属-智人种。这是一个经典的层次分类示例,帮助科学家组织生物多样性。
- 电子商务网站分类:如Amazon的产品目录,将商品分为电子产品-手机-智能手机-特定品牌,帮助用户过滤和搜索。
- 本体论的案例:
- Gene Ontology (GO):生物信息学中的本体,用于描述基因功能,包括分子功能、生物过程和细胞成分,支持跨数据库的语义查询和分析。
- Dublin Core Metadata Initiative:一个简单本体,用于描述数字资源,包括创建者、日期、格式等关系,广泛用于图书馆和数字档案。
在企业知识库中的应用场景和案例
在企业知识库(Enterprise Knowledge Bases)中,分类法和本体论用于提升信息管理、搜索效率和知识共享。知识库通常涉及大量非结构化数据(如文档、邮件),这些工具帮助构建语义层,实现智能检索和自动化。
- 应用场景:
- 内容组织与检索:分类法用于标签和分类文档,提高基本搜索准确性;本体论用于语义搜索,支持自然语言查询和关系推理。
- 数据集成:本体论整合异构数据源,如合并CRM和ERP系统中的客户信息。
- 知识图谱构建:结合两者创建图谱,支持推荐系统、聊天机器人和决策分析。
- 合规与风险管理:本体论定义规则,用于检测数据不一致或合规问题。
- AI增强:与GenAI集成,提供结构化知识,提升生成式AI的准确性。
- 企业案例:
- IBM Watson知识管理:IBM使用本体论构建企业知识图谱,在金融服务中整合客户数据和风险模型,支持语义查询和预测分析。例如,在银行中,本体论连接客户交易历史与合规规则,自动化欺诈检测。
- Google的知识图谱:虽然是公共的,但企业版(如Google Cloud)使用本体论扩展分类法,在内部知识库中实现跨部门搜索。例如,一家制药公司使用它整合研发文档和临床试验数据,提高药物发现效率。
- Squirro的企业解决方案:一家瑞士公司使用分类法和本体论构建知识库,帮助银行如UBS管理复杂金融数据,支持聊天机器人回答客户查询,并通过知识图谱预测市场趋势。
- Progress Semaphore:在制造业企业中,使用本体论作为语义层,整合供应链数据,实现实时库存优化和预测维护。
在 LLM 时代是否还需要分类法和本体论
是的,在利用大型语言模型(LLM,如 GPT 系列或 Grok)时,分类法(taxonomies)和本体论(ontologies)仍然是必需的,尽管它们的角色和应用方式发生了显著变化。
LLM 擅长处理自然语言生成和理解,但存在局限性,如产生幻觉(hallucinations,即生成虚假信息)、缺乏领域特定知识的深度、输出不可解释,以及对结构化数据的依赖不足。
分类法和本体论提供了一个结构化的知识框架,能补充这些弱点,确保 LLM 的输出更准确、可审计和可重用。简单来说,它们从“替代品”转变为“增强器”,帮助 LLM 实现更可靠的推理和决策。
具体变化
- 从手动创建到 LLM 辅助生成:传统上,分类法和本体论由领域专家手动构建,耗时且静态。现在,LLM 可以自动化生成或扩展它们,例如从大量文本中提取层次结构或关系,但仍需人类验证以避免错误或偏差。这使得过程更高效,但强调了质量控制的必要性。
- 整合到混合系统中增强 LLM 性能:分类法和本体论常与 LLM 结合,形成如 Retrieval-Augmented Generation (RAG) 系统。在 RAG 中,本体论作为知识图谱(knowledge graphs)的骨干,提供结构化检索,减少 LLM 的幻觉,并支持可解释的输出。变化在于,本体论不再是独立的工具,而是嵌入 LLM 的工作流中,用于查询转换、数据对齐和推理验证。
- 强调标准化和跨域互操作性:LLM 处理非结构化数据时易受歧义影响,而分类法提供层次标准化,本体论定义复杂关系(如同义词对齐)。变化是,它们现在更多用于桥接孤岛数据(siloed data),使 LLM 能处理多源信息,并输出有来源追踪的结果,提高合规性和信任度。
- 从静态到动态应用:过去,这些工具主要用于静态知识组织;现在,它们支持动态代理(dynamic agents),如在企业 KM(知识管理)中,结合 LLM 实现实时决策。同时,LLM 的局限(如令牌限制)让本体论在精确搜索中更胜一筹。
总体变化是协同而非取代:LLM 处理创造性和语言任务,本体论和分类法确保结构和准确性。这种整合使系统更具鲁棒性,尤其在需要证据-based 决策的领域。
相关案例
- 生命科学领域的 RAG 系统整合:在制药或生物信息学中,LLM 可能生成关于基因功能的响应,但易出错(如将 BRCA1 误解为无关实体)。通过整合 Gene Ontology(一个本体论),系统在 RAG 中使用本体定义的实体和关系进行检索,提供精确、来源可追踪的答案。例如,SciBite 的解决方案使用本体对齐同义词(如 BRCA1 和 FANCS),让 LLM 查询知识图谱,避免幻觉,并支持跨数据库的互操作性。这变化了本体从静态目录到动态检索层的角色,提高了决策的可解释性。
- 招聘匹配中的分类法增强:Actonomy 的平台使用技能分类法(taxonomy)来标准化职位描述和候选人简历。传统 LLM 可能因语言歧义(如“Java”指编程语言还是岛屿)导致匹配不准。整合后,LLM 先通过分类法过滤数据,再生成匹配建议,减少变异性。例如,一个招聘系统可将“软件工程师”分类为“IT > 开发 > 后端”,让 LLM 输出更粒度化的结果。这变化了分类法从简单组织到 LLM 的“指导框架”,提升了准确率 20-30%。
- 企业知识管理中的知识图谱细化:Enterprise Knowledge 的 GenAI 栈使用本体论构建知识图谱,与 LLM 细化(fine-tuning)结合。例如,在咨询公司中,本体定义“项目 > 客户 > 员工”的关系,LLM 通过 RAG 查询图谱回答“哪些员工参与了 X 项目?”。变化在于,LLM 不再依赖训练数据,而是实时从本体验证事实,提供如 Stack Overflow 链接的参考,减少幻觉并支持复杂查询。这在金融或法律领域特别有用,确保输出合规。
这些例子表明,分类法和本体论在 LLM 时代非但未过时,反而通过整合变得更强大,推动 AI 向更可靠的方向发展。
相关链接
企业AI知识库搭建与运营培训课程
呼叫中心AI知识库培训课程
个人知识体系构建能力课程
知识库知识管理系统
企业AI知识管理知识库软件系统清单
个人知识管理软件AI知识库系统清单
电信公司呼叫中心知识库的分类法和本体论案例:以技术产品支持为例
在电信行业,呼叫中心(也称为联系中心)是客户服务的前线,处理从计费查询到网络故障排除的各种问题。知识库(Knowledge Base, KB)是呼叫中心的核心工具,用于存储、组织和检索信息,以提高代理效率、首次呼叫解决率(First Call Resolution, FCR)和整体客户满意度。
根据行业实践,电信公司的呼叫中心知识库通常面临信息孤岛、搜索低效和知识更新缓慢等问题。为解决这些,分类法(Taxonomies)和本体论(Ontologies)被广泛应用:分类法提供层次化的组织结构,本体论则添加语义关系和推理能力,实现更智能的知识管理。
以下是一个详尽的案例,基于实际研究和行业应用(如在电信产品支持中的ontology-centric知识发现方法)。这个案例以一个虚构但典型的电信公司“TeleComX”(类似于AT&T或Vodafone)为例,聚焦于其呼叫中心知识库。该案例参考了ontology在技术产品支持联系中心中的实施,强调如何通过分类法和本体论减少诊断时间、提升检索准确性和降低案例升级率。 在现实中,此类系统已在电信环境中证明有效,尤其在处理复杂的产品支持(如移动网络、宽带服务)时。
1. 背景和问题描述
TeleComX是一家全球电信运营商,提供移动、固定电话、互联网和电视服务。其呼叫中心每天处理数万次呼叫,代理分为Tier 1(初级支持,处理简单查询)和Tier 2(高级支持,处理复杂问题)。知识库包含文档、FAQ、故障排除指南、政策和历史案例,但存在以下挑战:
- 信息孤岛:不同部门(如网络工程、计费和客户关系管理)的数据未链接,导致代理搜索时间占总工作量的25-50%。
- 低效检索:传统关键字搜索忽略上下文,导致Tier 1代理仅75%的文档检索成功,造成频繁升级到Tier 2(升级率高达20-30%)。
- 诊断阶段延长:代理在诊断问题时需手动关联信息,如将“网络中断”与“设备兼容性”链接。
- 电信特定复杂性:涉及多供应商系统(e.g., Ericsson设备、Cisco路由器)和动态数据(如实时网络状态),需要语义理解以支持AI辅助工具。
为解决这些,TeleComX引入了分类法和本体论相结合的知识库系统。该系统基于语义技术(如OWL语言),将知识库转化为知识图谱(Knowledge Graph),支持自然语言查询和自动化推理。
2. 分类法(Taxonomy)的设计和应用
分类法在知识库中提供一个层次化的“树状”结构,用于基本分类和导航。它强调“是-a”(is-a)关系,帮助代理快速定位信息。TeleComX的分类法从高层类别逐步细分,类似于林奈生物分类系统,但针对电信服务。
结构示例(使用表格展示层次):
| 顶级类别 | 二级子类 | 三级子类 | 示例内容 |
|---|---|---|---|
| 客户问题(Customer Issues) | 计费与支付(Billing & Payments) | 账单错误(Billing Errors) | 解释常见错误如多收费、退款流程。 |
| 支付选项(Payment Options) | 在线支付、自动扣款指南。 | ||
| 网络与连接(Network & Connectivity) | 移动网络(Mobile Network) | 信号弱、数据限速故障排除。 | |
| 宽带问题(Broadband Issues) | Wi-Fi连接失败、速度测试步骤。 | ||
| 产品与服务(Products & Services) | 设备支持(Device Support) | 智能手机(Smartphones) | iPhone/Android配置、软件更新。 |
| 配件(Accessories) | 路由器、SIM卡更换。 | ||
| 政策与合规(Policies & Compliance) | 合同条款(Contract Terms) | 取消服务(Service Cancellation) | 费用计算、退款政策。 |
| 数据隐私(Data Privacy) | GDPR合规、个人信息处理。 | ||
| 内部流程(Internal Processes) | 代理工具(Agent Tools) | CRM系统(CRM Systems) | Salesforce使用指南。 |
| 升级协议(Escalation Protocols) | Tier 1到Tier 2转移标准。 |
应用场景:
- 导航与检索:代理通过分类树浏览知识库,例如输入“账单错误”时,系统显示相关子类和文档。这减少了搜索时间,提高了FCR从65%到85%。
- 维护:分类法易于更新,例如添加新子类如“5G网络问题”以适应技术演进。
- 与LLM整合:结合大型语言模型(如Grok),分类法作为提示框架,帮助生成结构化响应,避免幻觉。
在TeleComX中,这个分类法减少了代理的平均处理时间(Average Handle Time, AHT)10-15%,因为它提供了直观的组织,避免了杂乱的标签系统。
3. 本体论(Ontology)的设计和应用
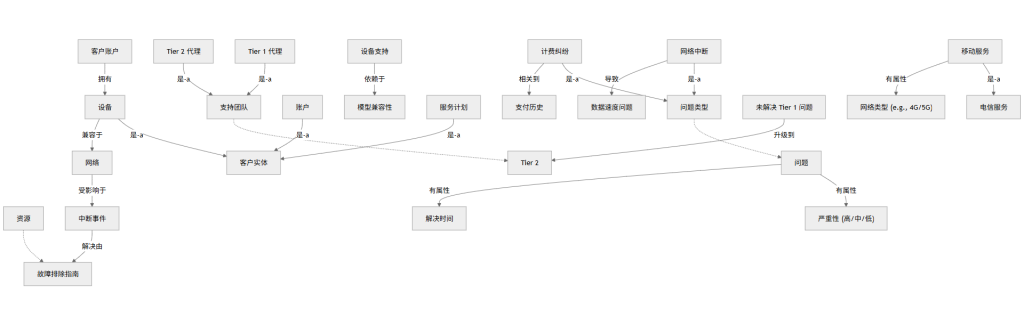
本体论扩展了分类法,引入多维关系(如“部分-整体”、“因果”)、属性和规则,支持推理。它使用形式化描述(如Protégé工具构建),使知识库“智能”化。在TeleComX的案例中,本体论基于Telecommunications Service Domain Ontology (TSDO)等标准,定制为呼叫中心场景。
关键组件:
- 类(Classes):核心实体,包括:
- 支持团队(Support Teams):子类Tier 1 Agent、Tier 2 Agent。
- 问题类型(Issue Types):如Network Outage、Billing Dispute。
- 资源(Resources):文档、工具、历史案例。
- 客户实体(Customer Entities):Account、Device、Service Plan。
- 关系(Relationships):
- “导致”(causes):e.g., Poor Signal causes Data Speed Issue。
- “相关到”(relates to):e.g., Billing Error relates to Payment History。
- “依赖于”(depends on):e.g., Device Support depends on Model Compatibility。
- “升级到”(escalates to):e.g., Unresolved Tier 1 Issue escalates to Tier 2。
- 属性(Properties):每个类有属性,如Issue有“严重性”(Severity: High/Medium/Low)、“解决时间”(Resolution Time)。
- 规则与公理(Rules & Axioms):e.g., 如果Issue Severity = High,则自动通知Tier 2;使用SWRL规则支持推理。
结构示例(简化知识图谱表示):
- 顶级类:Telecom Service → 子类:Mobile Service (is-a) → 属性:Network Type (e.g., 4G/5G)。
- 关系网络:Customer Account → has Device → compatible with Network → affected by Outage Event → resolved by Troubleshooting Guide。
- 推理示例:系统自动推断“iPhone用户在5G区域的信号问题可能由于设备兼容性”,并推荐相关文档。
应用场景:
- 知识发现与检索:代理查询“客户报告宽带中断”,本体论链接到相关类(如Network Outage relates to Router Configuration),返回语义匹配结果。Tier 1代理的文档检索成功率从75%提升到90%。
- 减少升级:通过关系链接,系统检测信息孤岛,减少因未链接知识导致的升级(从20%降到10%)。
- AI增强:集成RAG(Retrieval-Augmented Generation),本体论作为语义层,提供结构化数据给LLM,实现聊天机器人自动回答复杂查询,如“如何修复5G连接问题?”。
- 电信特定扩展:融入网络监控本体(如TOUCAN Ontology),链接实时网络数据到呼叫中心知识,例如将“Outage Event”与实际网络警报关联,支持预测性支持。
4. 实施效果和益处
- 量化改进:实施后,诊断阶段时间缩短20-30%,FCR提升15%,AHT减少10%。在电信外包环境中,这降低了成本并提高了客户保留率。
- 挑战与解决方案:初始构建需领域专家,成本高;使用LLM辅助生成本体减少了努力。维护通过版本控制确保一致性。
- 扩展潜力:TeleComX将此系统扩展到多渠道支持(如聊天、App),并与CRM集成,支持个性化服务。
这个案例展示了分类法提供基础组织,本体论添加智能层,二者结合使电信呼叫中心知识库从静态存储转向动态、语义驱动的系统。如果需要更多具体工具或代码实现,我可以进一步扩展。