提示词工程Prompt Engineering vs 上下文工程Context Engineering vs 管控工程Harness Engineering:2026 年有何区别?
核心要点
理解这三种 AI 工程方法,对于构建可靠、能产生可量化商业价值的系统至关重要,而非只做出效果惊艳的演示 Demo。
- 提示词工程:通过精心设计的指令优化单次交互,适用于内容生成等简单任务,但在生产环境中稳定性差
- 上下文工程:管理多轮对话的完整信息流,决定 AI 模型可访问的数据,同时处理记忆与工具调度
- 管控工程:搭建具备安全护栏、监控与控制机制的生产级基础设施,可将问题解决率提升最高 64%
- 策略性叠加三层方法:先用提示词快速见效,复杂工作流加入上下文管理,上线前部署管控基础设施
- 生产失效源于架构缺陷,而非仅提示词不佳:95% 的企业 AI 试点项目失败,根源是系统设计不足,而非指令质量问题
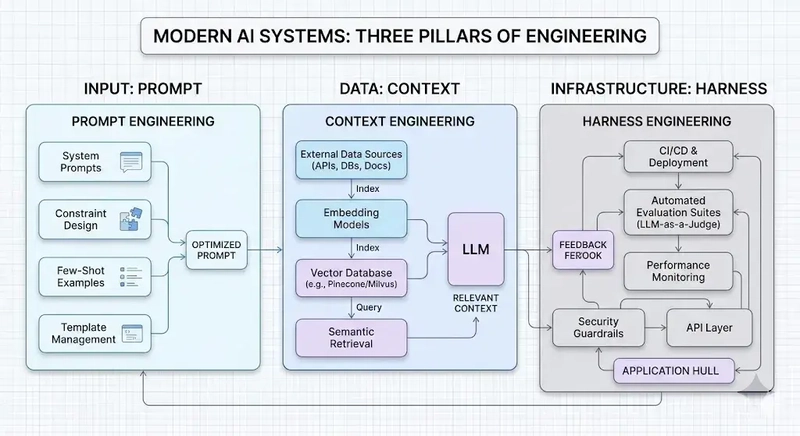
关键洞察:应将 AI 模型视为需要精细集成的引擎,而非独立解决方案。上下文工程隶属于管控工程,提示词工程则同时嵌套于二者之中,形成层级体系,每层分别应对不同的可靠性与复杂度需求。
研究显示,AI 智能体约有 20% 的失败率;麻省理工学院近期研究发现,大型企业中约 95% 的生成式 AI 试点项目未能实现可量化回报。这些数据暴露出 AI 系统构建方式的重大缺陷。如今问题已不再只是写出更好的提示词。随着 AI 从简单任务转向复杂工作流,我们需要理解三种截然不同的工程方法:提示词工程、上下文工程与管控工程。普林斯顿大学研究表明,相比基础配置,管控方案可将问题解决率提升 64%。本文将拆解每种方法的作用、差异,以及如何选用以实现最优 AI 性能。
什么是提示词工程
提示词工程通过结构化自然语言输入,让生成式 AI 模型输出指定结果。简单来说,就是用自然语言而非代码编写指令,引导 AI 生成目标回复。
提示词工程的工作原理
核心是设计包含特定模块的提示词:
- 指令:定义模型需执行的任务
- 主体内容:待处理或转换的文本
- 示例:通过输入 – 输出样本展示预期行为(小样本学习);零样本提示则直接给出指令、无需示例
- 引导词:启动模型输出
- 辅助内容:影响回复但非核心目标
思维链提示将复杂问题拆解为连续步骤,引导模型进行逻辑推理。温度参数调节输出随机性:低值(0.2)输出更聚焦,高值(0.7)更具创造性。研究显示,提示词效果对示例顺序、措辞等选择高度敏感,仅调整示例顺序就可导致准确率波动超 40%。
提示词工程的优势场景
最适合简单直接的任务:摘要、翻译、问答、内容生成。团队可快速原型开发功能、自动化重复工作,无需大量机器学习投入即可挖掘数据价值。适用于简单查询或对精度要求不高的创意场景,部署成本低、见效快。
提示词工程在生产环境中的局限
在生产环境中极其脆弱。看似无害的措辞微调就可能引发灾难性变化。例如将 “输出严格合法 JSON” 改为 “始终使用干净可解析的 JSON 回复”,就可能出现多余逗号或字段缺失,导致下游解析器崩溃。某工程复盘显示,仅为优化对话流畅性新增三个词,就使结构化输出错误率在数小时内急剧飙升。
提示词难以版本化、测试与跨团队标准化。还会出现静默失效:输出看似通顺,实则存在事实偏差或偏见。因此,提示词工程会成为维护负担,无法作为生产系统的可扩展方案。
什么是上下文工程
上下文工程设计系统,在生成回复前决定 AI 模型可获取的信息。提示词工程优化单条指令,而上下文工程构建模型周边的完整信息环境,包括对话历史、检索文档、用户偏好、可用工具与结构化输出格式。
上下文工程的工作原理
将上下文窗口视为有限的工作内存与注意力预算。大语言模型存在上下文退化问题:Token 数量增加,模型精准回忆信息的能力下降。上下文工程筛选最小可用高价值 Token 集合,最大化任务效果。
通过构建流水线动态拉取相关数据、过滤噪声、合理排序信息;借助 RAG 检索外部知识,维护多轮交互状态,将工具输出整合为连贯上下文。核心工程问题是在大模型固有限制下优化 Token 效用。
上下文工程的核心组件
包含六大要素:
- 系统指令:定义行为准则与运行边界
- 记忆管理:短期对话状态与长期持久知识
- 检索信息:从数据库、API 获取实时数据
- 工具调度:定义 AI 可调用功能及结果回流方式
- 输出结构化:确保回复遵循预设格式
- 查询增强:将杂乱用户输入转化为可处理请求
每个组件都需要对提供什么上下文、何时提供做出明确架构决策。
上下文工程 vs 提示词工程:核心差异
- 提示词工程:关注怎么措辞;优化单次交互;失效源于表述模糊;调试靠语言优化
- 上下文工程:关注模型需要知道什么;管理全系统多轮信息流;失效源于文档错误、信息过时、上下文溢出;调试需数据架构优化(检索调优、无关 Token 剪枝、工具顺序优化)
提示词工程是上下文工程的子集,在更大的信息生态中负责指令设计。
什么是管控工程
当团队意识到仅靠模型能力无法保证 AI 系统可靠性时,管控工程应运而生。它为 AI 智能体构建完整外围基础设施:约束条件、反馈循环、调度层与控制机制,将原始模型输出转化为生产级可用系统。
管控工程的工作原理
将 AI 模型视作需要精细集成的引擎。管控系统通过摘要与状态持久化管理超出上下文长度的会话记忆,保证连续性;通过协议调度工具访问,通过质量关卡校验输出,通过校验器与结构测试强制架构边界;认证、错误恢复、指标日志均在管控层实现。
研究显示,仅调整管控配置,问题解决率相较基线提升 64%。同一模型(Claude Opus 4.5)在不同管控下得分从 2% 提升至 12%,6 倍性能差距完全由环境设计决定。
管控工程的三大支柱
基于 Birgitta Boeckeler 框架:
- 上下文工程:持续更新知识库与动态可观测数据
- 架构约束:通过确定性校验器与结构测试设立边界
- 垃圾回收:定期扫描文档漂移与约束违规
管控工程 vs 上下文工程:关系解析
上下文工程是管控工程的子集,而非并行领域。
- 上下文:决定模型输入哪些信息
- 管控:额外增加约束、监测、控制与修复机制
OpenAI 通过将智能体失效作为优化信号,构建了百万行级代码产品且无手动编写源码;Stripe 通过管控限定任务范围、沙箱运行、审核关卡,每周自动生成 1300 个 AI 编写的合并请求。
管控工程 vs 提示词工程:系统 vs 指令
- 提示词工程:优化单次交互,用语言告诉模型做什么
- 管控工程:架构跨天、跨周的多步系统,通过机制强制保障数千次推理的可靠性,维护状态、校验输出、防止架构漂移
相关链接
经典培训课程
企业AI知识库搭建与运营培训课程
呼叫中心AI知识库培训课程
个人知识体系构建能力课程
书籍和资料
《卓越密码如何成为专家》
《你的知识需要管理》
免费电子书《企业知识管理实施的正确姿势》
免费电子书《这样理解知识管理》
知识库知识管理系统
企业AI知识管理知识库软件系统清单
个人知识管理软件AI知识库系统清单
三种工程方法的适用场景
选择依据:任务复杂度、可靠性要求、运行范围。
提示词工程:简单任务
适用于边界明确的单次交互,如快速内容生成、摘要、翻译。适合快速原型开发、无 ML 基础设施的数据价值挖掘。营销文案初稿、客服初步回复等,偶尔不准确不会带来重大商业风险的场景。
上下文工程:复杂工作流
当 AI 需要记忆历史对话、访问多数据源、执行长周期任务时使用。凡是超出简单内容生成的 AI 应用,都需要上下文工程。它为智能体提供清晰目标、相关知识与自适应感知,让演示变成可靠工具。
管控工程:生产系统
当 AI 涉及客户数据、财务信息、合规流程时必须部署。生产环境需要安全护栏、监控、故障恢复机制,这些只有管控工程能提供。
三者结合使用
高效 AI 系统会三层叠加:提示词在检索流水线 curated 的上下文内编写指令,管控系统则为数千次推理设立边界并监测性能。
对比总表:提示词工程 / 上下文工程 / 管控工程
表格
| 属性 | 提示词工程 | 上下文工程 | 管控工程 |
|---|---|---|---|
| 定义 | 结构化自然语言输入,引导生成式 AI 输出指定结果 | 设计系统,决定 AI 生成前可访问的信息 | 构建 AI 智能体完整基础设施:约束、反馈、调度、控制机制 |
| 核心聚焦 | 用自然语言编写指令 | 管理模型完整信息环境 | 搭建带安全、监控、控制的生产级系统 |
| 核心问题 | “该如何措辞?” | “模型需要知道什么?” | “如何让智能体在数千次推理中稳定运行?” |
| 适用范围 | 单次交互 | 全系统多轮信息流 | 跨天 / 周的多步系统 |
| 核心组件 | 指令、内容、示例、引导词、思维链、温度参数 | 系统指令、记忆管理、检索信息、工具调度、输出结构化、查询增强 | 上下文工程、架构约束、垃圾回收机制 |
| 最佳场景 | 简单任务:摘要、翻译、问答、生成、原型开发 | 需记忆、多数据源、长任务的复杂工作流、AI 智能体 | 涉及客户 / 财务 / 合规数据的生产系统 |
| 失效原因 | 表述模糊、措辞脆弱、静默失效 | 文档错误、信息过时、上下文溢出、退化 | 未重点提及,核心是通过设计预防失效 |
| 调试方式 | 语言优化 | 数据架构、检索调优、Token 剪枝 | 将智能体失效作为信号优化管控 |
| 性能影响 | 示例顺序可致准确率波动 > 40% | 在模型限制下优化 Token 效用 | 配置可提解决率 64%,同模型性能差 6 倍 |
| 生产适配性 | 有限:脆弱、难版本化、难测试、维护成本高 | 中等:管理信息流,但需额外基础设施 | 高:专为生产设计,带安全护栏与监控 |
| 相互关系 | 上下文工程的子集 | 管控工程的子集 | 包含上下文工程,外加约束、监测、控制、修复 |
| 真实案例 | 营销初稿、客服回复建议 | 带记忆与工具的 AI 智能体 | OpenAI 百万行代码产品、Stripe 周生成 1300 个 AI PR |
| 使用时机 | 单次交互,偶尔出错风险低 | 超出简单生成,需记忆 / 多源 / 长任务 | 要求高可靠性、安全、生产级性能 |
结论
提示词、上下文、管控三者并非二选一。先用提示词快速见效,工作流复杂后加入上下文,上线前叠加管控基础设施,AI 系统才能从惊艳 Demo 变为可靠生产力。模型提供能力,而工程方法决定这种能力能否转化为可量化的商业价值。
常见问题
Q1:提示词工程与上下文工程的核心区别?
提示词工程关注指令措辞、语气、结构,告诉模型 “怎么思考”;上下文工程决定 AI可访问的信息,定义模型 “能基于什么推理”。再完美的提示词也无法弥补上下文缺失或过时。
Q2:何时用提示词工程,何时用管控工程?
提示词:简单单次任务,如生成、翻译、摘要,偶尔出错影响小。
管控:处理敏感数据的生产系统,提供安全护栏、监控与故障恢复,支撑大规模可靠部署。
Q3:三种方法能否一起用?
可以,且是构建健壮 AI 系统的推荐方案。提示词写指令,上下文管理信息环境,管控保障边界与性能,让 AI 从演示变为生产工具。
Q4:为什么增加上下文反而会降低 AI 性能?
大模型存在上下文退化:Token 越多,精准回忆能力越差。只有高相关上下文才有价值,大量文本会淹没关键信息;历史记忆与当前状态冲突也会导致错误。因此上下文工程聚焦最小高价值 Token 集。
Q5:为什么提示词工程不适合生产环境?
极度脆弱,微小措辞变动可引发系统崩溃;难以版本化、系统化测试与跨团队标准化;易出现静默失效,最终成为维护负担,不具备可扩展性。